library(respondeR)
#> respondeR 0.1.0: impute responder proportions from continuous outcomes.
#> Analyze arm summaries with responder_analysis(); launch the app with launch_responder_analysis().
#> Docs: https://choxos.github.io/respondeR/ | GitHub: https://github.com/choxos/respondeRThe idea
Trials of continuous outcomes usually report a mean change and standard deviation in each arm. Those are hard to communicate: a standardized mean difference of 0.3 means little to a patient. A responder analysis translates the continuous result into something concrete: the proportion of patients who improve by at least a minimal important difference (MID). It contrasts the arms on familiar scales: risk difference, risk ratio, odds ratio, number needed to treat.
respondeR does this from summary statistics alone, using the cut-point approach of Anzures-Cabrera, Sarpatwari & Higgins (2011). It never needs individual patient data.
Data format
One row per study. The experimental arm columns end in
_e, the control arm in _c:
sample_responder_data
#> study change_e sd_e n_e change_c sd_c n_c
#> 1 Study 1 0.9581395 1.257593 43 0.217777778 1.195501 45
#> 2 Study 2 0.7920863 1.281364 139 0.003448276 1.324629 145
#> 3 Study 3 1.0230769 1.341201 156 -0.041975309 1.263178 162| Column | Meaning |
|---|---|
study |
Study label |
change_e, change_c
|
Mean change per arm |
sd_e, sd_c
|
SD of change per arm |
n_e, n_c
|
Sample size per arm |
A first analysis
Suppose a change above 1 is clinically meaningful. With
the default settings, responder_analysis() returns one row
per pooling method:
res <- responder_analysis(sample_responder_data, mid = 1)
res[, c("method", "p_e", "p_c", "rd", "rd_lb", "rd_ub", "rr", "or", "nnt")]
#> method p_e p_c rd rd_lb rd_ub rr
#> 1 individual NA NA 0.2554475 0.1869705 0.3239244 2.148809
#> 2 weighted 0.4742782 0.2205372 0.2537410 0.1985865 0.3088955 2.150558
#> 3 unweighted 0.4767051 0.2279613 0.2487438 NA NA 2.091167
#> 4 median 0.4869694 0.2150781 0.2718912 NA NA 2.264151
#> or nnt
#> 1 3.198098 3.914699
#> 2 3.188531 3.941027
#> 3 3.085185 4.020201
#> 4 3.464085 3.677941-
p_e,p_care the experimental and control responder proportions (on the[0, 1]scale). -
rd,rr,or,nntare the between-arm contrasts, each with a confidence interval (*_lb,*_ub). - The
individualmethod pools per-study risk differences, so it reports a pooledrdbut leavesp_e/p_casNA.
For a quick, readable summary use
format_responder_results():
format_responder_results(res)
#> Method PE PC RD RR
#> 1 Individual - - 25.5 (18.7 to 32.4) 2.15 (1.71 to 2.70)
#> 2 Weighted mean 47.4 22.1 25.4 (19.9 to 30.9) 2.15 (1.79 to 2.58)
#> 3 Unweighted mean 47.7 22.8 24.9 2.09
#> 4 Median 48.7 21.5 27.2 2.26
#> OR
#> 1 3.20 (2.30 to 4.45)
#> 2 3.19 (2.44 to 4.16)
#> 3 3.09
#> 4 3.46Which way is “better”?
By default a higher change is a response. For outcomes where
lower is better (pain, symptom scores), set
direction = "lower":
responder_analysis(sample_responder_data, mid = 1, direction = "lower",
method = "individual")[, c("method", "rd", "rd_lb", "rd_ub")]
#> method rd rd_lb rd_ub
#> 1 individual -0.2554475 -0.3239244 -0.1869705Baseline risk: matched or median control
By default each summary method pools the control arm the same way as
the experimental arm. To instead hold the baseline risk at the median
control arm for every summary method, as in the simulation study behind
this package (Sofi-Mahmudi, 2024), set control = "median".
This returns point estimates, because the median control arm has no
variance model:
responder_analysis(sample_responder_data, mid = 1, control = "median")[,
c("method", "p_e", "p_c", "rd")]
#> method p_e p_c rd
#> 1 individual NA NA 0.2554475
#> 2 weighted 0.4742782 0.2150781 0.2592001
#> 3 unweighted 0.4767051 0.2150781 0.2616270
#> 4 median 0.4869694 0.2150781 0.2718912Per-study results and a forest plot
responder_rd_individual() returns the per-study risk
differences that feed a forest plot:
responder_rd_individual(sample_responder_data, mid = 1)
#> study p_e p_c rd se ci_lb ci_ub
#> 1 Study 1 0.4867232 0.2564577 0.2302655 0.10023645 0.03380566 0.4267253
#> 2 Study 2 0.4355507 0.2259278 0.2096229 0.05454152 0.10272350 0.3165223
#> 3 Study 3 0.5068639 0.2047187 0.3021452 0.05106129 0.20206690 0.4022235
ps <- responder_rd_individual(sample_responder_data, mid = 1)
pooled <- responder_analysis(sample_responder_data, mid = 1, method = "individual")
y <- rev(seq_len(nrow(ps) + 1))
est <- c(ps$rd, pooled$rd) * 100
lo <- c(ps$ci_lb, pooled$rd_lb) * 100
hi <- c(ps$ci_ub, pooled$rd_ub) * 100
labels <- c(as.character(ps$study), "Pooled")
op <- par(mar = c(4, 6, 1, 1))
plot(NA, xlim = range(c(lo, hi, 0)), ylim = c(0.5, length(y) + 0.5),
yaxt = "n", xlab = "Risk difference (%)", ylab = "", bty = "n")
abline(v = 0, lty = 2, col = "grey60")
segments(lo, y, hi, y, lwd = 2)
points(est, y, pch = c(rep(15, nrow(ps)), 18), cex = c(rep(1.4, nrow(ps)), 2))
axis(2, at = y, labels = labels, las = 1, tick = FALSE)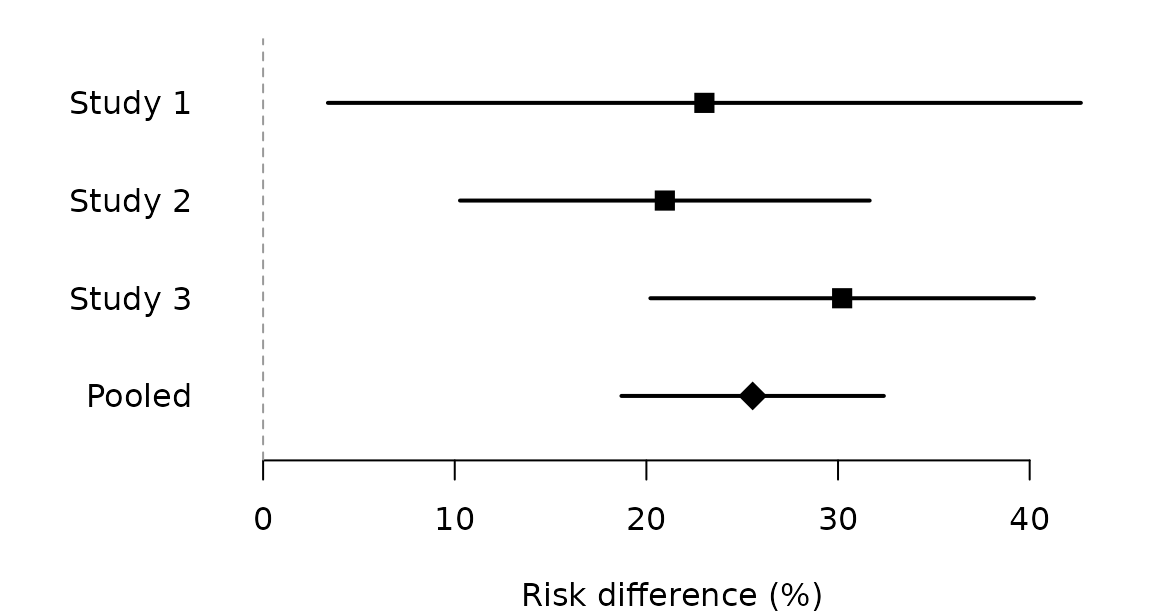
par(op)Random effects and heterogeneity
When studies disagree, use random-effects pooling. respondeR reports Cochran’s Q, I-squared, tau-squared and a prediction interval:
responder_analysis(sample_responder_data, mid = 1, method = "individual",
pooling = "random")[, c("method", "rd", "rd_lb", "rd_ub",
"tau2", "i2", "pi_lb", "pi_ub")]
#> method rd rd_lb rd_ub tau2 i2 pi_lb pi_ub
#> 1 individual 0.2554475 0.1869705 0.3239244 0 0 -0.18848 0.6993749A threshold-free alternative
Choosing a MID is sometimes contentious. The common-language effect size sidesteps it entirely: the probability that a randomly chosen treated patient responds better than a randomly chosen control.
cles <- responder_cles(sample_responder_data)
sprintf("CLES = %.1f%% (%.1f%% to %.1f%%)",
100 * cles$cles, 100 * cles$cles_lb, 100 * cles$cles_ub)
#> [1] "CLES = 69.0% (65.1% to 72.7%)"A real example: VAS pain after exercise therapy
The package bundles a real dataset, vas_pain: the 20
randomized trials of exercise for spinal health pooled for the visual
analogue scale (VAS) pain outcome by Li, Bao, Wang and Zhao (2025). The
change scores are post minus baseline VAS on a 0 to 10 cm scale, so a
more negative value is a larger pain reduction; we analyze with
direction = "lower" and a negative MID equal to the
responder threshold. Using a 1.5 cm reduction as the minimal important
difference:
res <- responder_analysis(vas_pain, mid = -1.5, direction = "lower",
pooling = "random", ci_method = "hksj")
format_responder_results(res)
#> Method PE PC RD RR
#> 1 Individual - - 17.5 (10.6 to 24.3) 1.19 (1.08 to 1.32)
#> 2 Weighted mean 84.4 63.4 21.0 (18.2 to 23.7) 1.33 (1.28 to 1.38)
#> 3 Unweighted mean 78.7 47.1 31.6 1.67
#> 4 Median 83.9 37.3 46.7 2.25
#> OR
#> 1 3.22 (2.27 to 4.57)
#> 2 3.11 (2.63 to 3.68)
#> 3 4.14
#> 4 8.81Pooling the per-study estimates (the individual method,
the most defensible), about 17 more exercise patients per 100 reach a
1.5 cm pain reduction than controls. The pool-then-dichotomize summaries
give larger and more dispersed values here (weighted about 21,
unweighted about 32, median about 47 per 100): that spread is a sign of
heterogeneity across the 20 trials, and the individual method, which
respects each trial’s own scale, is the one to trust. The threshold-free
common-language effect size avoids picking a cut-point:
cles <- responder_cles(vas_pain, direction = "lower")
sprintf("A treated patient has less pain than a control %.0f%% of the time (%.0f%% to %.0f%%)",
100 * cles$cles, 100 * cles$cles_lb, 100 * cles$cles_ub)
#> [1] "A treated patient has less pain than a control 71% of the time (68% to 74%)"(Data from Li et al. (2025), Frontiers in Sports and Active Living, , Figure 3, reproduced under CC BY 4.0.)
The Shiny application
Everything above is available in a point-and-click app:
The same tool runs in the browser, with no installation, at https://choxos.github.io/respondeR/app/.
Where next
See vignette("methodology") for the full statistical
detail: each method’s estimator and variance, the relative measures, the
SMD bridge, the logit/MID-uncertainty/distribution options, assumptions
and a method-choice guide.